China is the Last Hope to Stop NVIDIA’s Monopoly

On December 9, China launched an antitrust investigation into the US chipmaker Nvidia. The company could face fines of up to $1.03 billion, according to the South China Morning Post.
Global Times reported that the investigation primarily concerns an acquisition. In 2019, Nvidia announced its $6.9 billion acquisition of Mellanox Technologies, the largest acquisition deal of that year. The concern was that Nvidia’s purchase of Mellanox would enable it to complete a near-monopoly in the AI industry, a market the US International Trade Administration estimated that will to add $15 trillion to global economy by 2030, which also drew scrutiny from antitrust authorities in the European Union and the United States. However, it seems China is the only country to stop Nvidia’s monopoly.
To understand why, we need to first grasp how Nvidia’s monopoly operates:
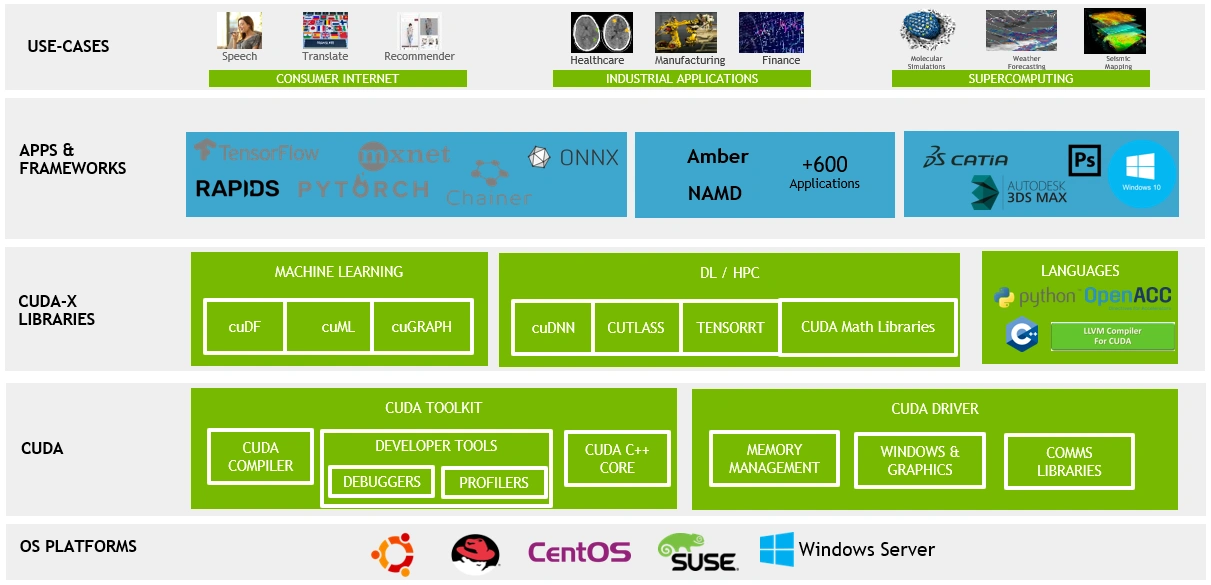
To train a competitive AI, three core components are essential: hardware, software, and communication technology. Nvidia has established a global monopoly over the first two.
In terms of hardware, Nvidia’s H100 is currently the best-selling AI training chip worldwide. According to Nasdaq, Nvidia sold an estimated $38 billion worth of H100 GPUs in 2023, as companies raced to acquire the chips for training large language models. This surge in demand propelled Nvidia to the forefront of the AI chip market, securing a market share of over 90%.

Mizuho Securities estimates that Nvidia controls between 70% and 95% of the AI chip market, specifically for training and deploying models like OpenAI’s GPT. The H100, when purchased directly from Nvidia, is priced at approximately $25,000. Nvidia’s pricing power is reflected in a remarkable 78% gross margin—This vividly demonstrates how much Nvidia exploits technology companies after gaining a monopoly position.
In terms of software, Nvidia’s most formidable competitive advantage is the Compute Unified Device Architecture (CUDA).
The competition for AI models initially stemmed from the rivalry between Google and Meta. Engineers discovered that while CPUs excel at general computing and meet the requirements for inference tasks in AI, they were insufficient for handling the large-scale parallel computing tasks required for deep learning, especially for training large models. GPUs, with their powerful parallel processing capabilities, were better suited for this purpose. However, their programming models and memory access patterns differed significantly from those of CPUs, creating considerable development challenges.
To solve this, Nvidia introduced CUDA in 2007, enabling developers to use C/C++ to tap into the parallel processing power of GPUs for non-graphical workloads. This innovation laid the foundation for deep learning, prompting major frameworks like TensorFlow and PyTorch to integrate native support for CUDA early on.
 CUDA quickly became the most efficient path to harness the computational power of GPUs. According to the Netflix Technology Blog, using a custom CUDA kernel, the training time for a neural network on a cg1 instance was reduced from over 20 hours to just 47 minutes when processing 4 million samples.
CUDA quickly became the most efficient path to harness the computational power of GPUs. According to the Netflix Technology Blog, using a custom CUDA kernel, the training time for a neural network on a cg1 instance was reduced from over 20 hours to just 47 minutes when processing 4 million samples.
In the academic world, most papers demonstrating innovations in neural networks defaulted to using CUDA acceleration when conducting GPU-based experiments, further cementing its dominance in the emerging deep learning community.
Meanwhile, Qualcomm, Intel, and Google have reportedly teamed up to offer oneAPI as an alternative to Nvidia’s CUDA, but these efforts have largely faltered. The reason for this is simple: once developers invest in the CUDA ecosystem, switching to other GPU frameworks becomes a daunting challenge. It requires rewriting code, learning new tools, and often re-optimizing the entire computing process. These high switching costs make it more practical for many companies and developers to continue relying on Nvidia’s products, rather than risk exploring alternative solutions.
Even tech giants like Google, with the resources to invest heavily in custom ASICs, have struggled to replace CUDA. In 2018, Nvidia GPUs accounted for over 90% of Google’s TPUv2 infrastructure, despite the company’s substantial investments in custom hardware.
In terms of communication technology, Nvidia’s acquisition of Mellanox has raised concerns in China, the US, and the EU.
As AI models continue to grow in size, large language models now require hundreds of gigabytes, if not terabytes, of memory just for their model weights. For example, production recommendation systems deployed by Meta require dozens of terabytes of memory for their massive embedding tables. A significant portion of the time spent on training or inference for these large models isn’t dedicated to matrix multiplications, but rather to waiting for data to reach the compute resources.
To address this challenge, InfiniBand—a computer networking standard used in high-performance computing that boasts extremely high throughput and low latency—has been introduced into the AI training industry. According to The Institute of Electrical and Electronics Engineers (IEEE), InfiniBand now dominates AI networking, accounting for roughly 90% of deployments.
Mellanox has been the leading supplier of InfiniBand technology. As of 2019, Mellanox connected 59% of the TOP500 supercomputers, with a year-over-year growth of 12%, showcasing its dominance and continued advancement in InfiniBand technology.
 Jensen Huang met with Mellanox CEO Eyal Waldman
Jensen Huang met with Mellanox CEO Eyal Waldman
By acquiring Mellanox, Nvidia secures the “holy trinity” of the AI industry—domination in GPU chips, development tools, and communication technologies for distributed computing. This acquisition further strengthens Nvidia’s monopoly in AI, creating a snowball effect that makes it increasingly difficult for competitors to break through.
When China’s Administration for Market Regulation approved Nvidia’s acquisition of Mellanox in April 2020, it imposed additional restrictive conditions. These included prohibiting Nvidia from bundling GPUs and networking devices, and from discriminating against customers who purchase these products separately in terms of price, function, and after-sales service. However, in June 2022, Nvidia explicitly stated in the user agreement for CUDA 11.6 that it bans the use of CUDA-based software on third-party GPUs. This effectively forces developers using AMD and Intel chips to switch to Nvidia’s GPUs, prompting China to launch an investigation into Nvidia last week for potential violations of antitrust law.
By now, many of you may understand why China is investigating Nvidia. However, the question remains: why is China only starting this review now, two years after Nvidia allegedly broke the law? This delay can be attributed to three key factors.
Firstly, China’s chipmakers have finally developed the technology to challenge Nvidia.
The Nvidia H100 GPU is manufactured using TSMC’s N4 process, which is categorized as a “5 nm” process by the IEEE International Roadmap for Devices and Systems. While, ASML is only allowed to sell DUV machines to China, primarily used for producing 7 nm chips.
According to Bloomberg, SiCarrier—a Chinese chipmaking equipment developer collaborating with Huawei—secured a patent in late 2023 involving Self-Aligned Quadruple Patterning (SAQP). This breakthrough allows for certain technical achievements akin to those seen in 5 nm chip production. Business Korea argued in May that chips made using such techniques would cost four times as much as those produced with EUV lithography, Huawei’s actions appear to bust this claim. On November 26, Huawei launched its Mate 70 Pro, with the 1TB version priced at 7,999 CNY—the same price as the Mate 60 Pro with similar specifications released the previous year.

On December 9, Huawei’s executive director, Yu Chengdong, publicly announced that the chips in the Mate 70 series are 100% made in China. Technode reported that the Huawei Mate 70 Pro’s CPU, the Kirin 9020, outperforms Qualcomm’s Snapdragon 8+ Gen 1, which was released in 2022 and manufactured using TSMC’s N4 process. According to insiders, while the Kirin 9020 chip may still uses a 7nm transistor process, its advanced packaging technology has greatly enhanced computing efficiency.
The successful launch of the Huawei Mate 70 Pro demonstrates that Chinese chipmakers can now produce chips competitive with TSMC’s 5nm technology in large quantities and at competitive prices. This achievement also positions them to extend their expertise to GPUs, provided they adapt their designs to meet the specific requirements of each processor type. This advancement suggests that Chinese chipmakers are nearing the capability to produce GPUs with hardware performance comparable to Nvidia’s H100.
Moreover, The Financial Times reports that China’s biggest chipmaker SMIC has put together new semiconductor production lines in Shanghai, aiming to produce 5nm chips. Although 5nm chips remain a generation behind the current cutting-edge 3nm ones, the move would show China’s semiconductor industry is still making gradual progress, despite US export controls.

Secondly, Chinese AI companies are increasingly positioned to reduce their dependence on CUDA.
American companies like Google and Meta remain heavily reliant on CUDA because it offers the best acceleration performance for Nvidia’s H100 chip, which dominates the AI hardware market. However, the CHIPS and Science Act, signed by President Biden, prohibited Nvidia from exporting H100 chips to Chinese companies after 2022. This restriction has forced Chinese technology giants such as Baidu and Tencent to explore alternatives, including AMD GPUs and domestically developed GPU chips, effectively reducing their reliance on Nvidia’s CUDA ecosystem.
In addition, Moore Threads, a Chinese GPU design company, launched its Moore Threads Unified System Architecture, MUSA, on November 5. The MUSA architecture, a serious challenger to CUDA, provides a high-performance, flexible, and highly compatible computing platform that supports various parallel computing tasks, including AI computation, graphics rendering, multimedia applications, and physical simulation. The company also provides a wealth of development tools and libraries, such as MUSA SDK, AI acceleration libraries, communication libraries, etc., to help developers better develop and optimize applications. Moreover, MUSA is compatible with CUDA’s software stack interface, significantly easing the process of porting applications and lowering the cost for enterprises to move away from Nvidia products.
 Moore Threads’ MTT S4000 AI GPU is already available in December 2023
Moore Threads’ MTT S4000 AI GPU is already available in December 2023
Thirdly, InfiniBand technology is becoming outdated compared to Chinese Ethernet advancements.
While InfiniBand currently dominates AI networking with approximately 90% of deployments, IEEE reports that Ethernet is emerging as a strong contender for AI clusters. For instance, InfiniBand often lags behind Ethernet in terms of maximum speeds. Nvidia’s latest Quantum InfiniBand switch reaches 51.2 Tb/s with 400 Gb/s ports, whereas Ethernet achieved 51.2 Tb/s nearly two years ago and now supports port speeds of up to 800 Gb/s.
One challenge for Ethernet adoption has been its inability to handle the massive workloads of AI training and other high-performance computing (HPC) applications. The high traffic levels in data centers can lead to bottlenecks, causing latency issues that make it unsuitable for these tasks.
However, on September 27, during the 2024 China Computational Power Conference, state-owned China Mobile and 50 other partners introduced Global Scheduling Ethernet (GSE)—a new networking protocol designed to handle large data volumes and provide high-speed transfers tailored to AI and other HPC workloads.

Since Nvidia’s acquisition of Mellanox in 2019, there are no longer independent suppliers of InfiniBand products. In contrast, Ethernet has a diverse range of suppliers worldwide. If China Mobile successfully promotes Ethernet technology as a replacement for InfiniBand in AI applications, it could provide AI companies globally with access to local suppliers, potentially reducing costs and fostering competition.
China is not the only country challenging Nvidia’s monopoly. However, it is the most determined and resourceful one. Due to U.S. sanctions, China’s own technological advancements and a vast domestic market, China has emerged as one of the few countries with significant independence and competitiveness in hardware, software, and communication technology. More importantly, these technology companies are not just owned by the state—they are driven by the ingenuity and efforts of the Chinese people.
As of October 2024, China boasts 1.1 billion internet users, accounting for 20% of the world’s total online population. When President Biden banned Chinese companies from purchasing the most advanced American chips and algorithms, it was the demand from these 1.1 billion users—who engage in activities such as watching short videos, gaming, and shopping online—that empowered Chinese tech companies to pursue self-reliance. According to official Chinese statistics, in 2023, the market size of China’s digital economy reached 53.9 trillion yuan.
Europe and the Global South undoubtedly have minds as brilliant as China’s. However, with Google and Meta leaving little room for competitors to emerge in these regions, they can never rely on the support of European and Global South users to get rid of Nvidia’s dominance. The free market is great, but if you only support it when it suits your needs, it might not work as it should.
Editor: Charriot Zhai
https://www.nasdaq.com/articles/if-youd-invested-%241000-in-nvidia-when-the-h100-was-launched-this-is-how-much-you-would
https://www.cnbc.com/2024/06/02/nvidia-dominates-the-ai-chip-market-but-theres-rising-competition-.html
https://medium.com/@aidanpak/the-cuda-advantage-how-nvidia-came-to-dominate-ai-and-the-role-of-gpu-memory-in-large-scale-model-e0cdb98a14a0#
https://medium.com/@1kg/nvidias-cuda-monopoly-6446f4ef7375
https://netflixtechblog.com/distributed-neural-networks-with-gpus-in-the-aws-cloud-ccf71e82056b
https://techblog.comsoc.org/2024/08/28/will-ai-clusters-be-interconnected-via-infiniband-or-ethernet-nvidia-doesnt-care-but-broadcom-sure-does/
https://www.cnbc.com/2024/06/02/nvidia-dominates-the-ai-chip-market-but-theres-rising-competition-.html
https://www.businesskorea.co.kr/news/articleView.html?idxno=217031
https://www.bloomberg.com/news/articles/2024-03-22/huawei-tests-brute-force-method-for-making-more-advanced-chips
https://app.myzaker.com/news/article.php?m=1733783919&pk=675621948e9f097fe428016b
https://technode.com/2024/11/27/huawei-launches-mate-70-series-with-new-kirin-9020-chip/
https://m.chinanews.com/wap/detail/chs/zw/10323437.shtml
https://www.tomshardware.com/networking/china-debuts-global-scheduling-ethernet-chip-to-deliver-networking-solutions-for-ai-aims-to-compete-with-the-ultra-ethernet-consortium-for-next-generation-interconnection-technologies
https://www.scmp.com/tech/big-tech/article/3290190/nvidia-faces-us1-billion-fine-if-china-probe-finds-violation-antitrust-laws-experts-say
https://www.gov.cn/yaowen/liebiao/202409/content_6976033.htm
https://www.gov.cn/lianbo/bumen/202409/content_6976495.htm
https://www.trade.gov/artificial-intelligence
https://www.ft.com/content/b5e0dba3-689f-4d0e-88f6-673ff4452977


Anonymous
I am continually amazed by China’s resilience given how aggressive the US acts. If it cant out innovate you it blocks, cheats, limits others so its not an even playing field. They are the Lance Armstrongs of the tech world and we know how it ended for him. Never give up and you will find a way, ways to excel and benefit mankind. I am eagerly waiting for Huawei to release its new Harmony OS for PC so I can get rid of american hardware and software. There are many of us waiting to change over to chinese ecosystems. We are tired of American hegemony, very tired.
Anonymous
Tonya Harding is the usual analogy used to describe US tactics.
Anonymous
China’s antitrust action against NVIDIA could be the pivotal move needed to break the company’s near-total dominance in the AI chip market. https://gsupertools.com/